In the previous devlog, I integrated ENet and implemented a network thread with support for sending and receiving basic messages.
My next goal was to implement replication support for entities and components. I wanted to leverage the ECS itself to drive this as much as reasonably possible by registering component types as replicable, flagging entities for replication, and using systems to process them accordingly. To that end, I formed a rough plan:
- Define a component for designating an entity as replicable and flagging it as dirty.
- Define a way of keeping track of component types that should be considered for replication.
- Define observers/systems to read entities awaiting replication (i.e. flagged as dirty) and serialise their relevant data.
- Implement sending of replication data to clients via ENet.
- Implement handling of replication requests on clients.
The replication component
I started by defining a component that can be used to mark an entity as replicable and keep track of when it’s dirty. I’m not sure whether I’ll stick with this approach for the “dirty” and “newly created” flags as it may be more efficient to use a set of tags instead, especially as they can be enabled/disabled (a feature of Flecs) to control when they get matched by queries. For now, though, the component by itself works just fine.
I wanted this component to be able to support delta replication by keeping track of which components have changed, so I included a set of component IDs and some utilities for working with it:
struct ReplicatedComponent{ bool mIsDirty = true; static constexpr size_t MAX_DIRTY_COMPONENTS = 64; flecs::id_t mDirtyComponents[MAX_DIRTY_COMPONENTS]; size_t mDirtyComponentCount = 0; float mLastReplicatedTime{0}; bool mIsNewEntity = true;
void MarkDirty(flecs::id_t componentId) { mIsDirty = true;
if (IsComponentDirty(componentId)) return;
if (mDirtyComponentCount < MAX_DIRTY_COMPONENTS) { mDirtyComponents[mDirtyComponentCount++] = componentId; } }
void ClearDirty() { mIsDirty = false; mDirtyComponentCount = 0; mIsNewEntity = false; }
bool IsComponentDirty(flecs::id_t componentId) const { if (mIsNewEntity) return true;
for (size_t i = 0; i < mDirtyComponentCount; ++i) { if (mDirtyComponents[i] == componentId) return true; }
return false; }};The replicated component registry
For component registration, I defined a simple registry API that wraps Flecs’ component registration and provides an optional way of registering a component for replication. It also handles entity observers (which flag entities for replication or destruction when added to or removed from the world) and component observers (which flag entities for replication based on replicable components being added/modified/removed).
This is what I ended up with:
struct ComponentDescriptor{ flecs::id_t mComponentId; size_t mSize; static constexpr size_t MAX_NAME_LENGTH = 128; char mName[MAX_NAME_LENGTH]; uint32_t mTypeHash;
ComponentDescriptor() = default; ComponentDescriptor(const std::string& name) { strncpy(mName, name.c_str(), MAX_NAME_LENGTH - 1); mName[MAX_NAME_LENGTH - 1] = '\0'; }};
class ComponentRegistry{public: ComponentRegistry(flecs::world& ecs) : mEcs(ecs) {}
template<typename T> flecs::component<T> RegisterComponent() { return mEcs.component<T>(); }
template<typename T> flecs::component<T> RegisterReplicatedComponent(const std::string& name) { flecs::component<T> type = this->RegisterComponent<T>();
ComponentDescriptor desc(name); desc.mComponentId = mEcs.id<T>(); desc.mSize = sizeof(T); desc.mTypeHash = Utils::HashString(name);
mIdToDescriptor[desc.mComponentId] = desc; mHashToId[desc.mTypeHash] = desc.mComponentId; mComponents.insert(desc.mComponentId);
this->InitComponentObserver<T>();
return type; }
const std::unordered_set<flecs::id_t>& GetReplicatedComponents() const { return mComponents; }
const ComponentDescriptor& GetDescriptor(const flecs::id_t componentId) const { return mIdToDescriptor.at(componentId); }
private: flecs::world& mEcs;
std::unordered_map<flecs::id_t, ComponentDescriptor> mIdToDescriptor; std::unordered_map<uint32_t, flecs::id_t> mHashToId; std::unordered_set<flecs::id_t> mComponents;
std::queue<uint64_t> mDestructionQueue;
void InitEntityObservers() { mEcs.observer<ReplicatedComponent>() .event(flecs::OnAdd) .each([](flecs::entity e, ReplicatedComponent& rep) { rep.mIsDirty = true; rep.mIsNewEntity = true; });
mEcs.observer<ReplicatedComponent>() .event(flecs::OnRemove) .each([this](flecs::entity e, ReplicatedComponent& rep) { mDestructionQueue.push(e.id()); }); }
template<typename T> void InitComponentObserver() { mEcs.observer<T, ReplicatedComponent>() .event(flecs::OnAdd) .each([](flecs::entity e, T& component, ReplicatedComponent& rep) { // Don't mark as dirty if the entity is new - that case is handled by the // entity OnAdd observer (see InitEntityObservers above) if (!rep.mIsNewEntity) { rep.MarkDirty(e.world().id<T>()); } });
mEcs.observer<T, ReplicatedComponent>() .event(flecs::OnSet) .each([](flecs::entity e, T& component, ReplicatedComponent& rep) { rep.MarkDirty(e.world().id<T>()); });
mEcs.observer<T, ReplicatedComponent>() .event(flecs::OnRemove) .each([](flecs::entity e, T& component, ReplicatedComponent& rep) { // Mark the entity as dirty so the removal can be replicated without // sending the component data rep.mIsDirty = true; }); }};I’m not completely happy with this as it shouldn’t directly handle the destruction queue. In fact, a queue shouldn’t be necessary at all as entities could be marked for destruction with a tag instead. As long as the entity has the tag for at least one frame, that gives the replication system the opportunity to tell clients to destroy their copies of the entity.
I’ll probably revisit this, but again, it’s good enough for now.
Serialisation and replication requests
To facilitate sending replication data to clients, it made sense to use the message system. I just needed decide what data to actually send for each entity and how to get it from the ECS into the network thread ready to send.
At a minimum, a single replication needs to include the entity ID, a component count, and the component data. Flags for ‘is new’ and ‘is destroyed’ also help the client apply the correct action (although ‘is new’ could be inferred from checking whether the given entity ID exists in the client’s ECS). I settled on this:
| Field | Size |
|---|---|
| Entity ID | 8 bytes |
| ’Is new’ flag | 1 byte |
| ’Is destroyed’ flag | 1 byte |
| Component count | 2 bytes |
| Component 0 type hash | 4 bytes |
| Component 0 data size | 2 bytes |
| Component 0 data | Variable |
| (More components…) | (…) |
Adopting this schema, I implemented a ReplicationRequest struct to represent a single replication action for a single entity. It’s an intermediate format that sits between the ECS on the main thread and ENet on the network thread. It looks like this:
struct ReplicationRequest{ struct ComponentData { uint32_t mTypeHash; std::vector<uint8_t> mData; };
// Serialized fields uint64_t mEntityId; bool mIsNewEntity; bool mIsDestroyed; std::vector<ComponentData> mComponents;
ENetPeer* mRecipient = nullptr;};mRecipient is used to specify a single peer to send the packet to. This is used for replicating full entity snapshots to newly connected clients. When it’s nullptr, the data is broadcast to all clients.
As a sidenote, I’ve not looked into compression yet. Superficial research suggests LZ4 might be a suitable algorithm for that, so I may try that out. Since I’m only testing functionality with a very small number of entities using a handful of components, it’s not a high priority.
I extended the server application loop to include an “update replication” step, which does two things:
- Queries dirty entities, generates replication requests for them, and passes them to the network thread.
- Reacts to newly connected clients, if any, by querying all replicated entities to generate full replication requests for them and passing them to the network thread.
The requests are placed in a queue and sent as messages at regular intervals. The overall thread flow on the server looks like this:
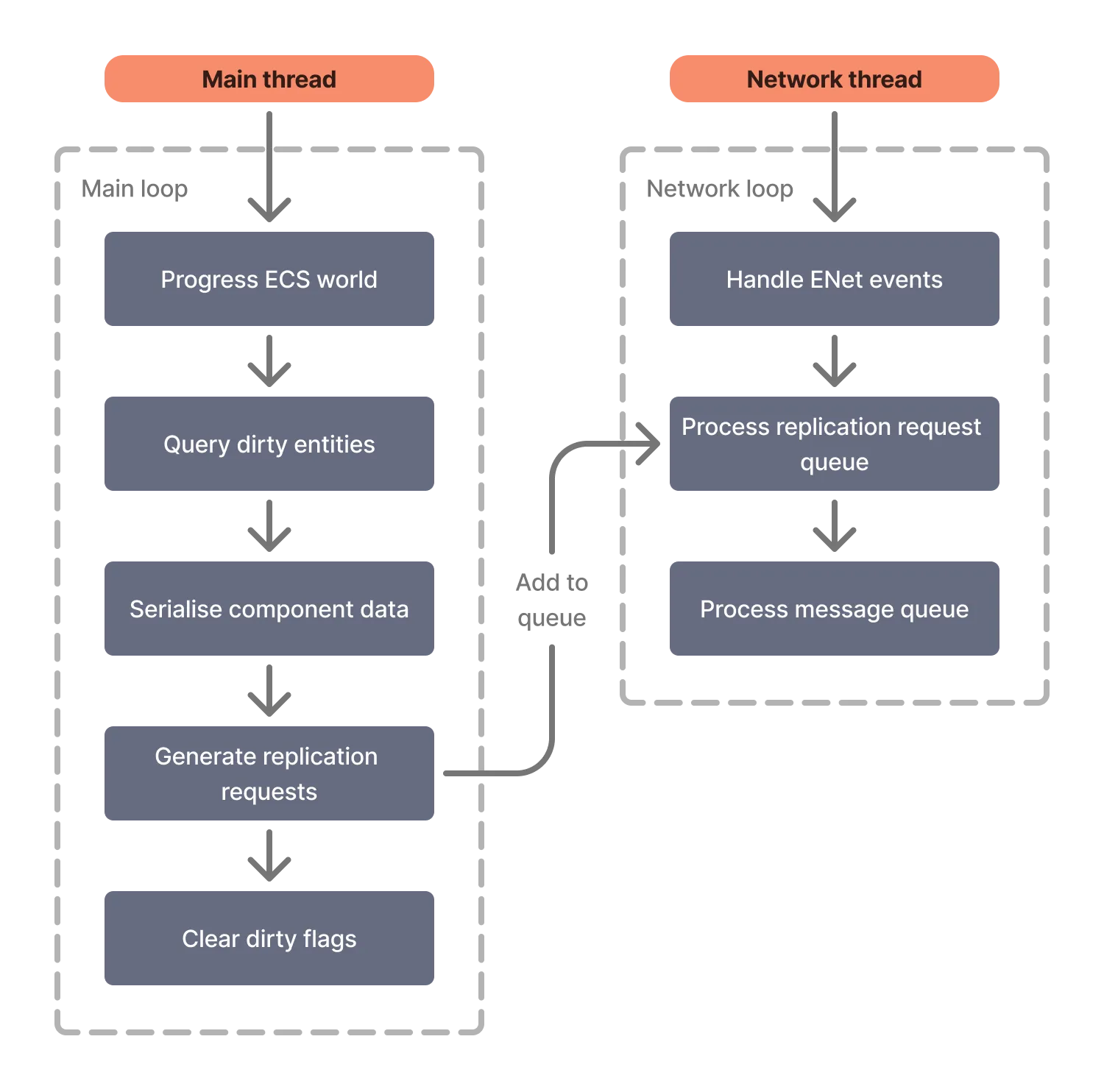
To simplify interpretation of messages, I designated the first two ENet channel IDs—0 for “general” messages (this will likely serve no real purpose, but could be useful for debugging) and 1 for replication messages.
Deserialisation
To receive and process replication messages, I updated ClientThread. The first thing I did was update its HandleEvent override, where I added a case for processing packets received on the replication channel, queuing up the deserialised replication data:
void ClientThread::HandleEvent(const ENetEvent& event){ NetworkThread::HandleEvent(event);
switch (event.type) { case ENET_EVENT_TYPE_DISCONNECT: spdlog::info("Disconnected"); mState = State::Idle; break;
case ENET_EVENT_TYPE_RECEIVE: { switch (event.channelID) { case Channel::Replication: { std::vector<uint8_t> data(event.packet->data, event.packet->data + event.packet->dataLength); auto request = ReplicationRequest::Deserialize(data);
{ std::lock_guard<std::mutex> lock(mReplicationMutex); mReplicationQueue.push(std::move(request)); }
enet_packet_destroy(event.packet); break; } } break; }
default: break; }}I then added a new method for processing the queue, creating or updating entities according to each replication request:
void ClientThread::ProcessReplicationQueue(fc::ECS::ComponentRegistry* registry){ std::queue<ReplicationRequest> queue; { std::lock_guard<std::mutex> lock(mReplicationMutex); queue.swap(mReplicationQueue); }
auto& ecs = registry->GetWorld();
while (!queue.empty()) { auto& req = queue.front();
flecs::entity e;
if (req.mIsNewEntity) { e = ecs.entity(); mServerToClientEntities[req.mEntityId] = e.id(); } else { auto it = mServerToClientEntities.find(req.mEntityId); if (it != mServerToClientEntities.end()) { e = ecs.entity(it->second); } else { spdlog::error("Received replication request for unknown entity {}", req.mEntityId); } }
if (req.mIsDestroyed) { e.destruct(); mServerToClientEntities.erase(req.mEntityId); } else { for (const auto& compData : req.mComponents) { flecs::id_t compId = registry->GetComponentId(compData.mTypeHash); if (compId != 0) { const ECS::ComponentDescriptor& desc = registry->GetDescriptor(compId); if (compData.mData.size() == desc.mSize) { e.add(compId); void* ptr = e.get_mut(compId); memcpy(ptr, compData.mData.data(), desc.mSize); e.modified(compId); } } } }
queue.pop(); }}Those changes were the last pieces needed to get fully functioning replication in my manual tests. To set up a basic test scenario, I registered PositionComponent and TextComponent as replicated components, added a server entity with both of those components added to it (along with the required ReplicatedComponent), then implemented a server-side system to update the entity with an incrementing timer in the TextComponent’s string. You can see a demonstration of the server running with two clients displaying the replicated entity below.
If you’d like to see the full code diff for the whole system, you can view the PR here.
What’s next
This is the first replication system I’ve designed and implemented, so I learned a lot and I’m pleased that it works. That said, I can already see lots of room for improvement. For example, the separation between the application layer and the network layer isn’t very clear. I should probably refactor this to introduce a dedicated serialisation/deserialisation layer.
I’ve also added a lot of functionality without writing a single test! Automated testing is not a topic I touched on in the previous devlogs and it’s not in my To Do list, but I should definitely add a testing framework and get some tests written—partly for practice, but mainly to add some resilience to the code so I can continue experimenting with new systems and features without fear of breaking everything and losing motivation.
Aside from that, the replication system could be optimised in a few ways. I could add compression (as mentioned earlier), batch the replication data on a per-client basis (ENet deals with splitting data across multiple UDP packets as necessary, so I don’t need to worry about that), make the delta replication smarter, etc. But some automated tests should probably come first.
Until next time, thanks for reading!